Yawei Li

Gloriastrasse 35, 8092 Zürich
Switzerland
I’m going to join Nanyang Technological University as a Nanyang Assistant Professor in 2026. Currently, I am a Lecturer at ETH Zürich. I work with Prof. Luca Benini. I also collaborate with Prof. Radu Timofte, Dr. Michele Magno, and Prof. Ming-Hsuan Yang. I got my PhD degree from the Computer Vision Lab supervised by Prof. Luc Van Gool. During my PhD, I was mentored by Babak Ehteshami Bejnordi, Tijmen Blankevoort, and Amir Habibian at Qualcomm and Rakesh Ranjan at Meta. After my graduation, I worked as a Postdoc at CVL, and part-time at Meta.
My research focuses on AI efficiency, aiming to accelerate computation, reduce memory footprint, and mitigate power consumption in AI systems. This is a fascinating area that drives AI applications across both cloud and edge environments. Addressing this challenge requires delving into the system stack to understand its fundamental units, from input modalities, models, computation mechanisms, mappings to hardware specifications. Through joint optimization across techniques and layers, it becomes possible to achieve extreme computational efficiency.
My research covers the topics on the following levels of AI system stack:
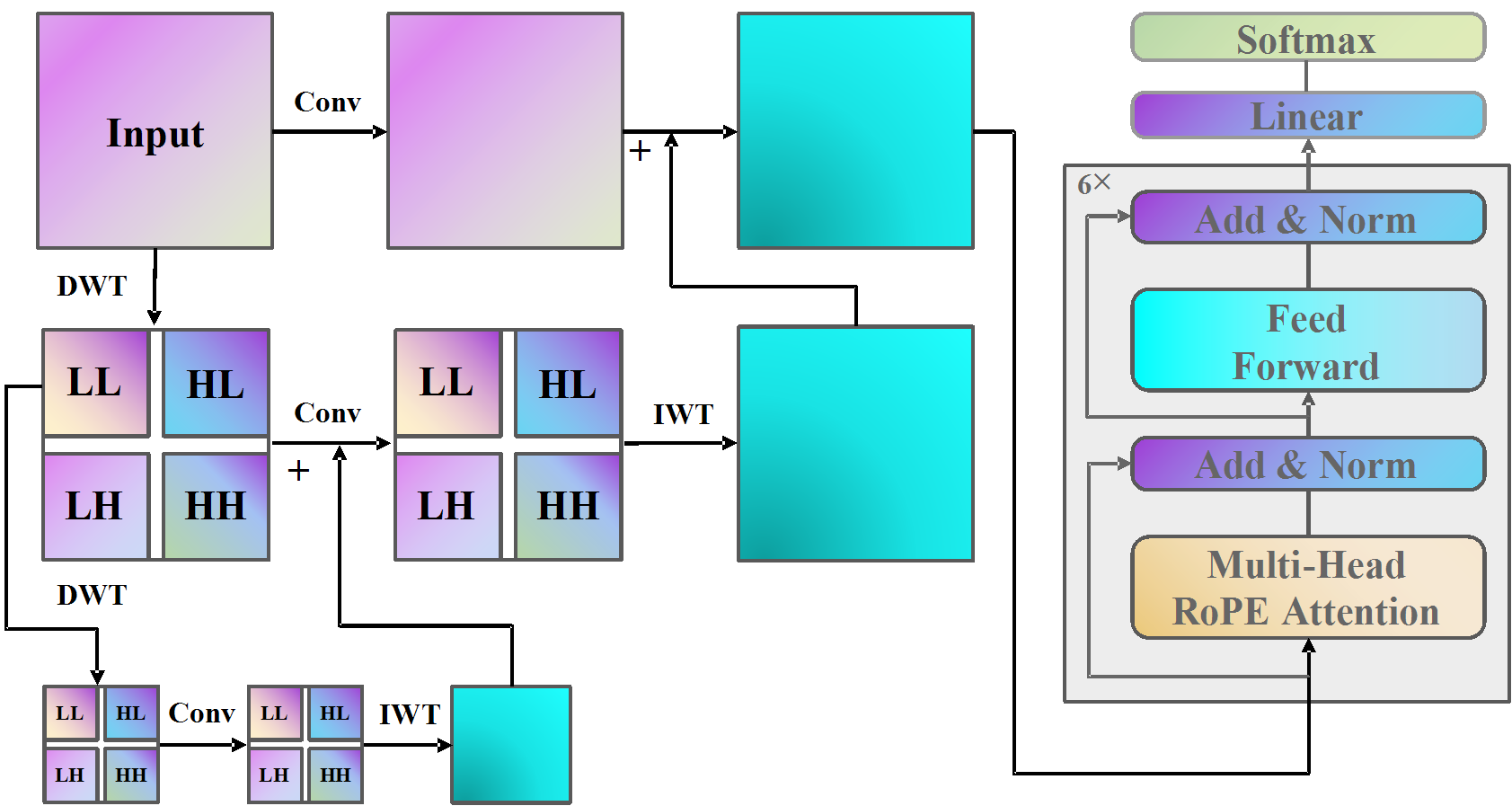
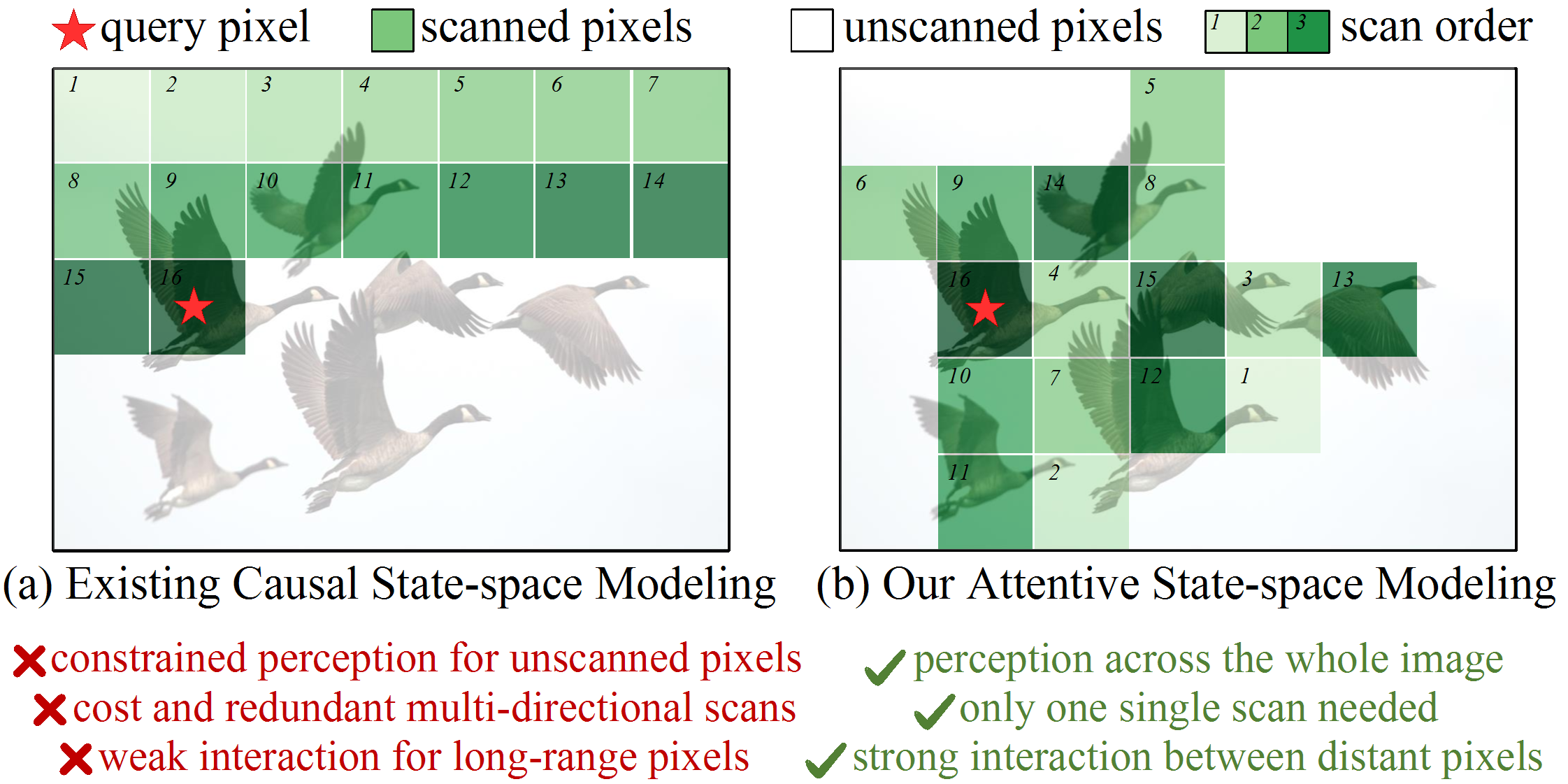
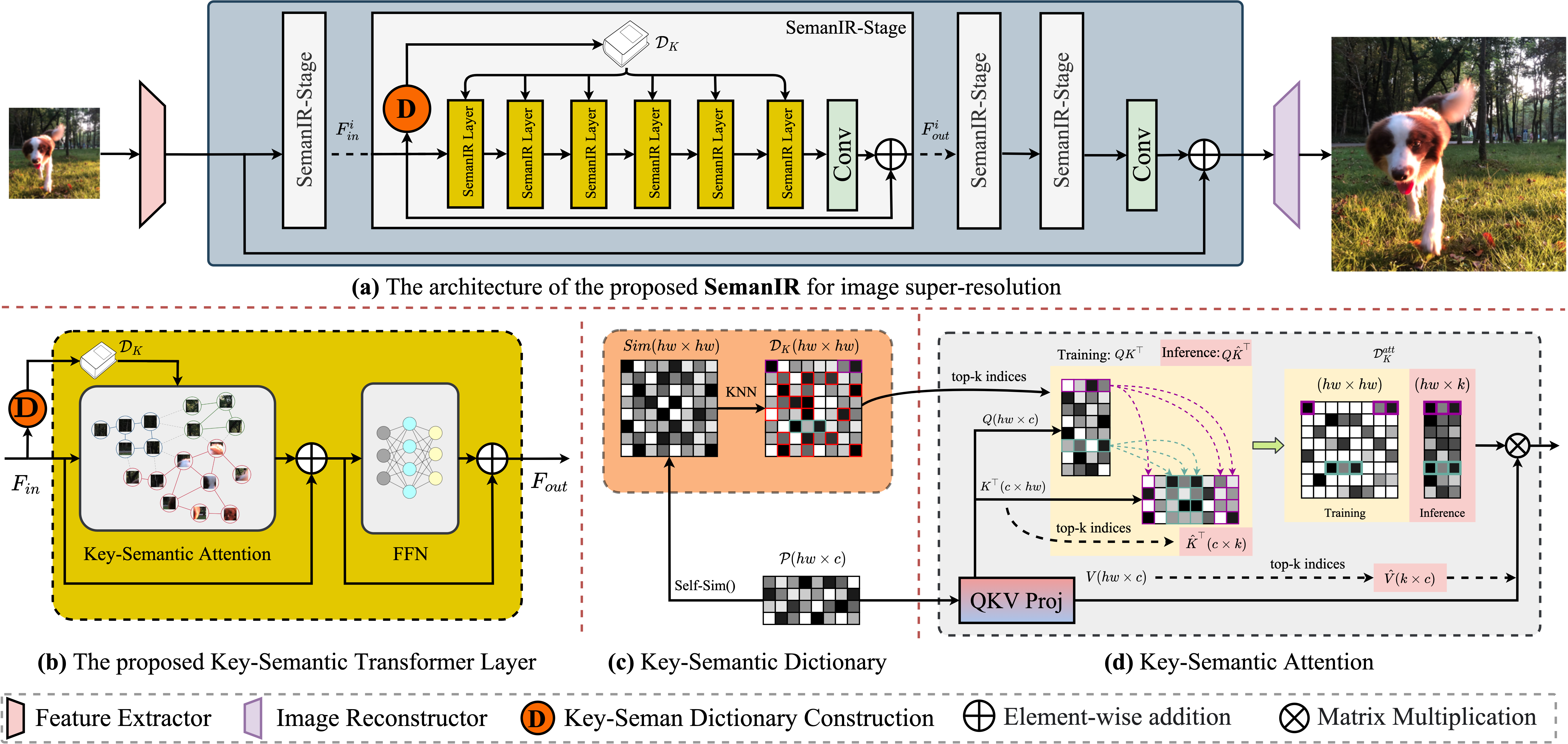
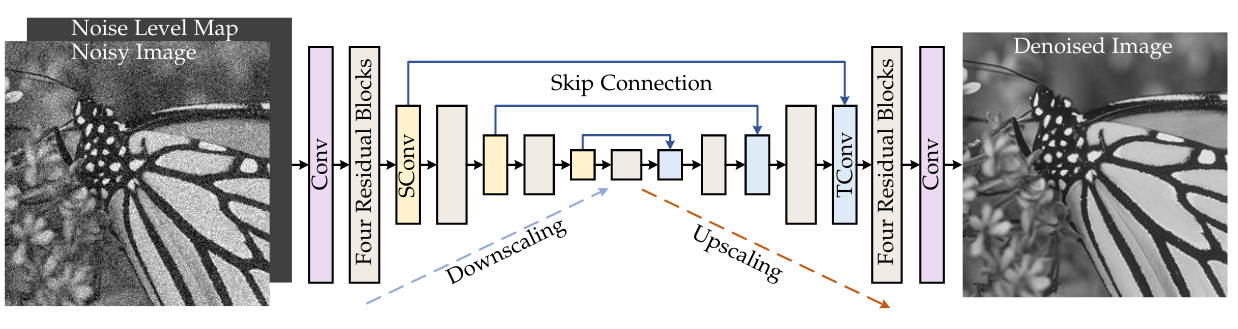
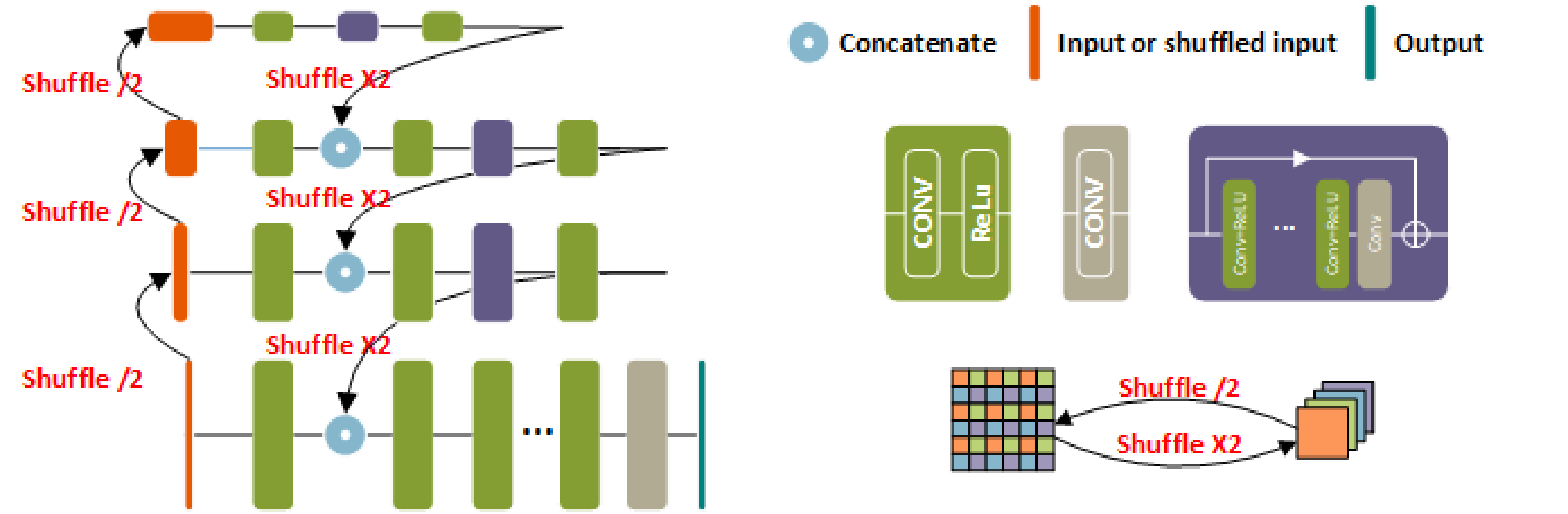
- Computational-efficient model design: My work investigate efficient computational mechnism for CNNs, graph neural networks, vision Transformers (LocalViT, GRL, SemanIR, VRT), and state-space models (MambaIR, FEMBA).
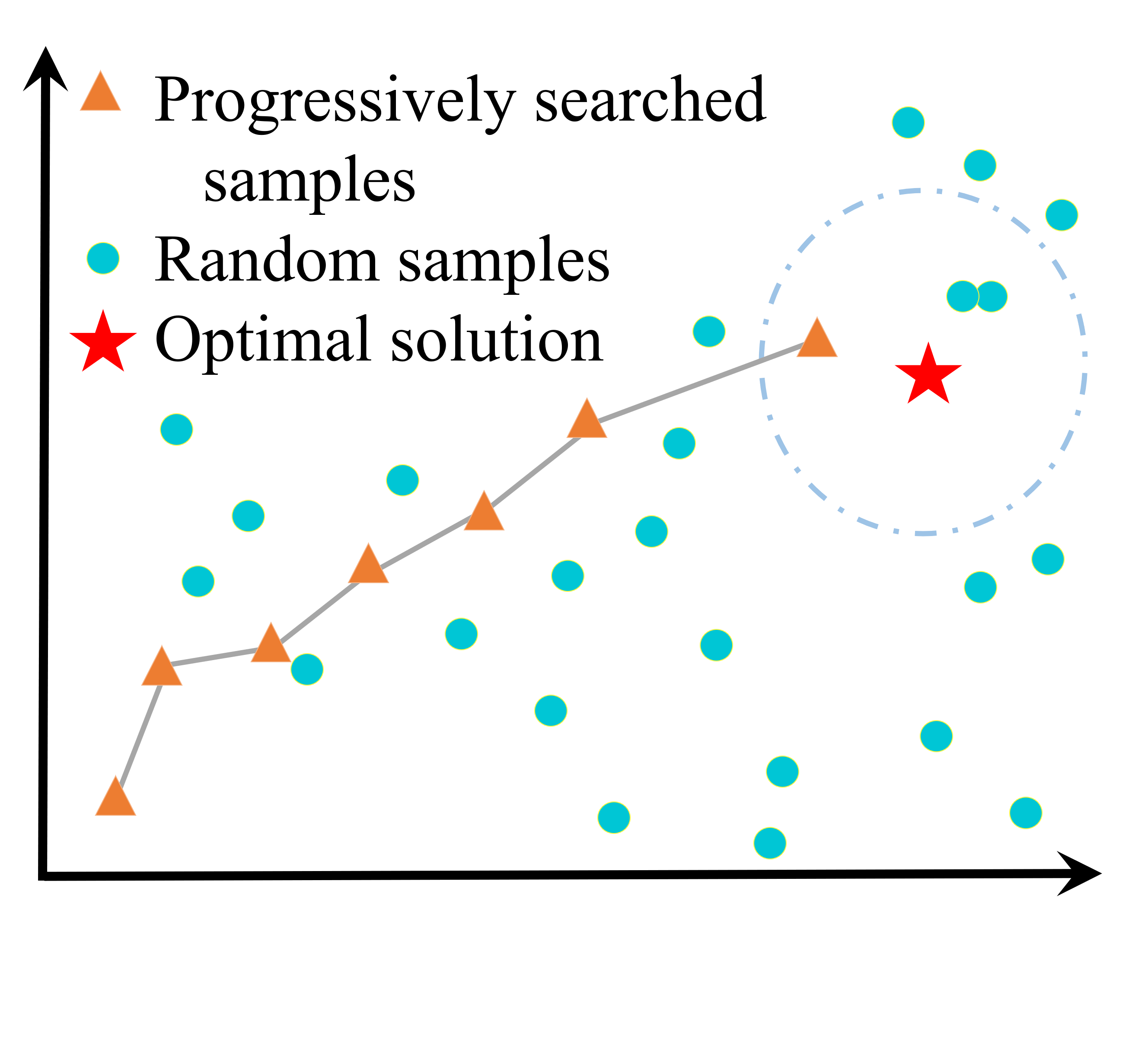
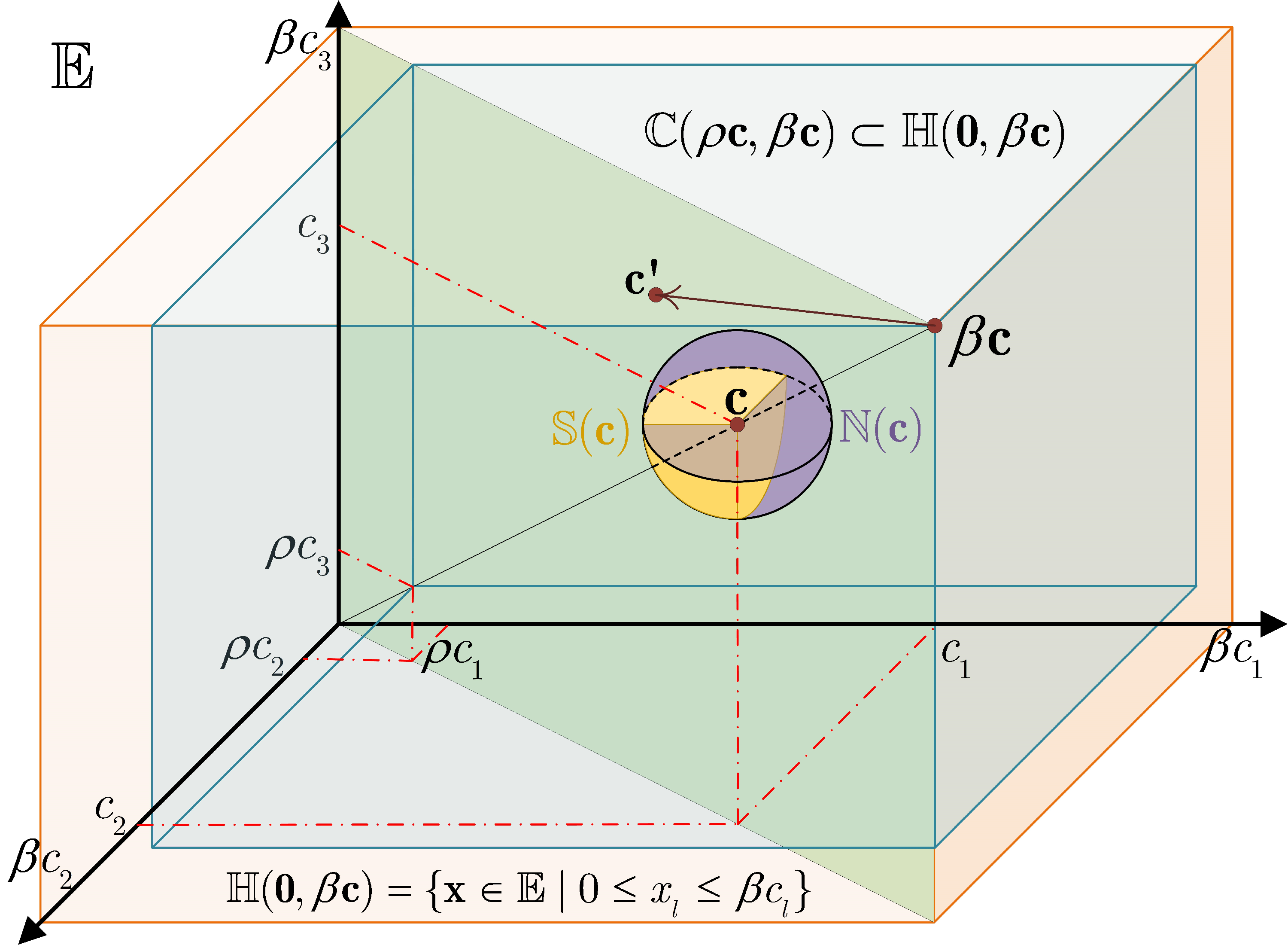
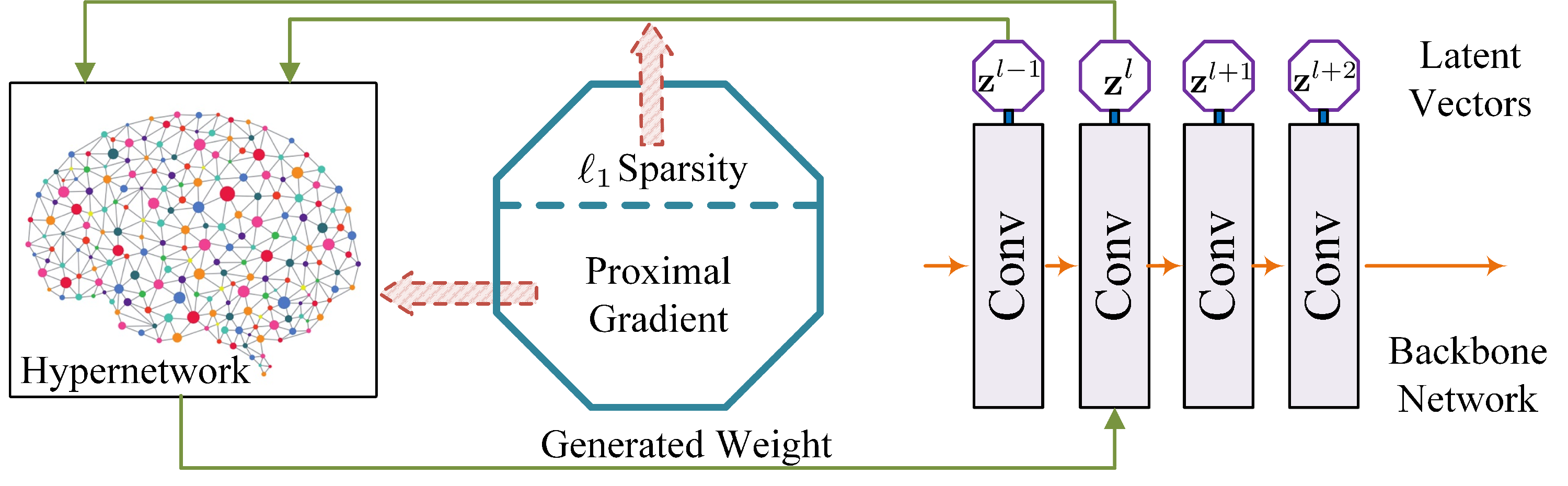
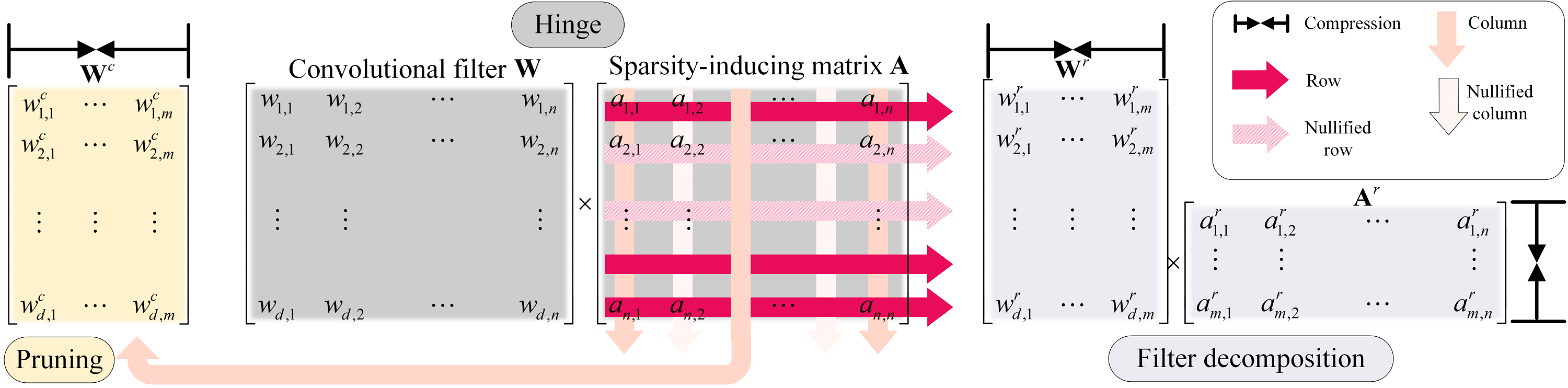
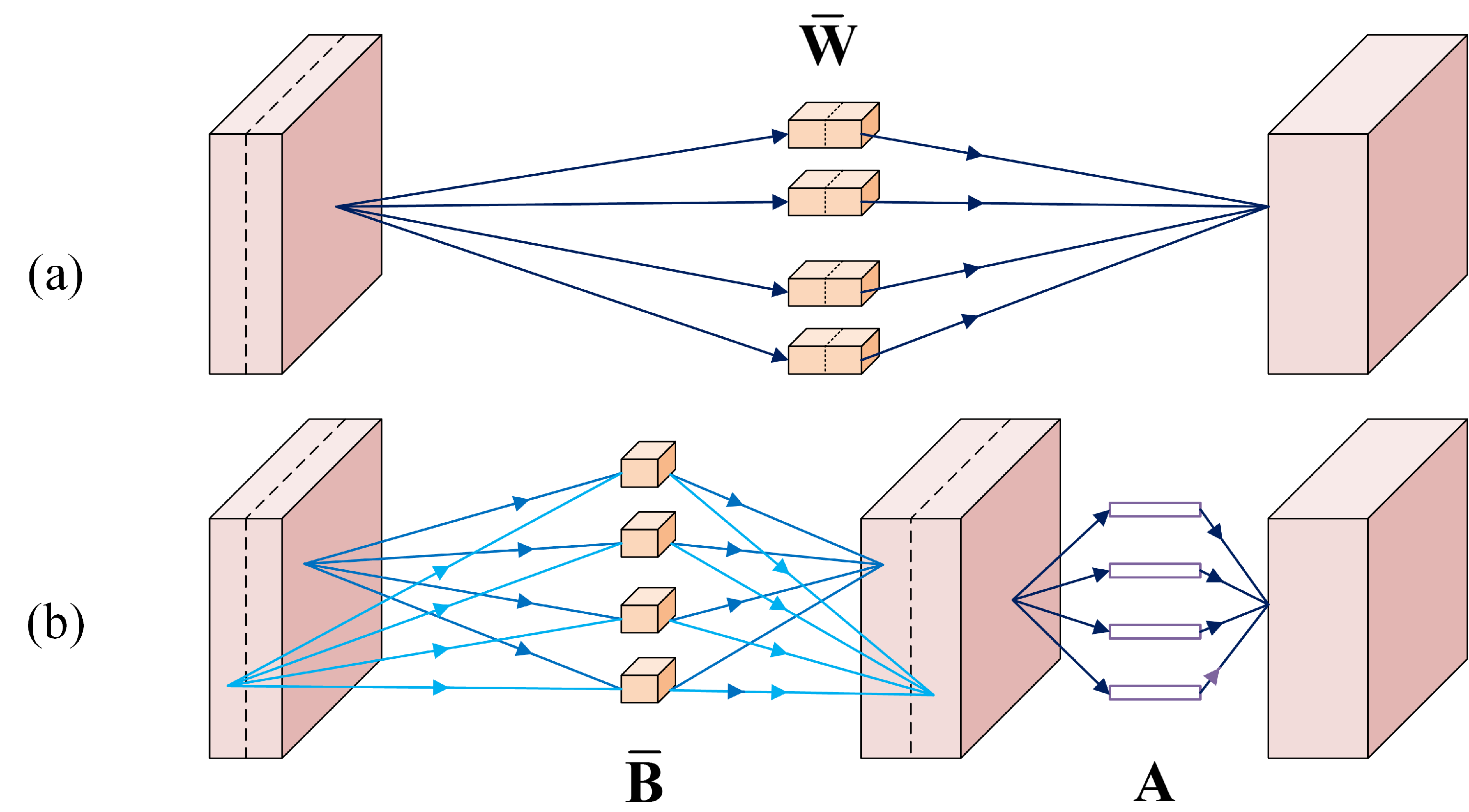
- Model compression and deployment: My work covers multiple model compression methods including model pruning (group sparsity, random pruning, DHP) token pruning (FastVAR), quantization (SliM-LLM, OBR), tensor decomposition(learning filter basis), and low-rank adaptation (IntLoRA) methods to compress LLMs and diffusion models.
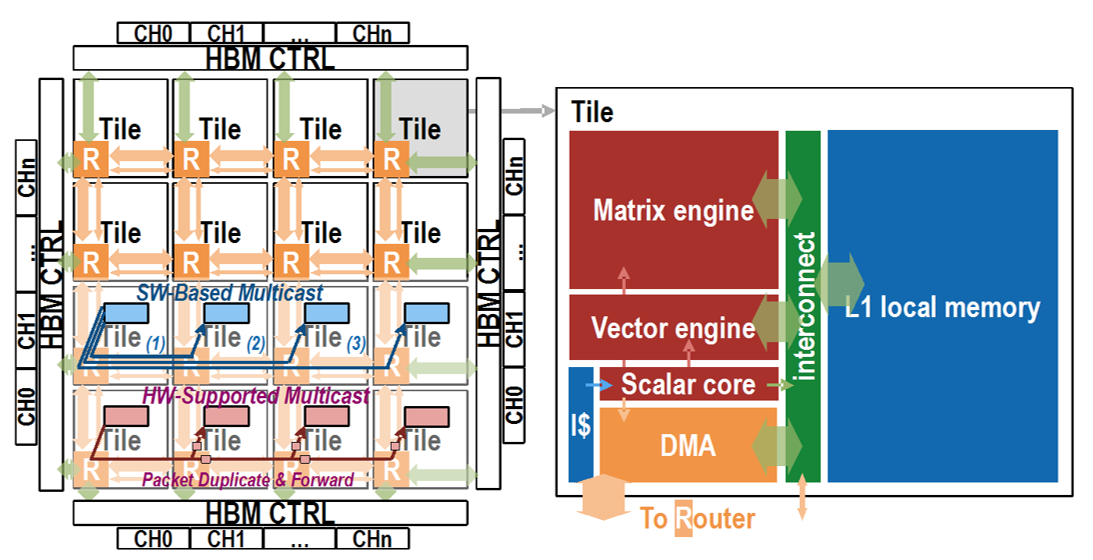
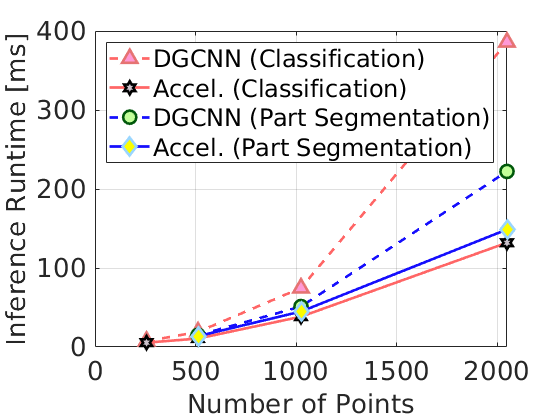
- Software-hardware co-design: I investigate how to co-design software and hardware to serve modern deep models efficiently on both large clusters (FlatAttention) and edge devices (smart glasses, Retina, TinyTracker).
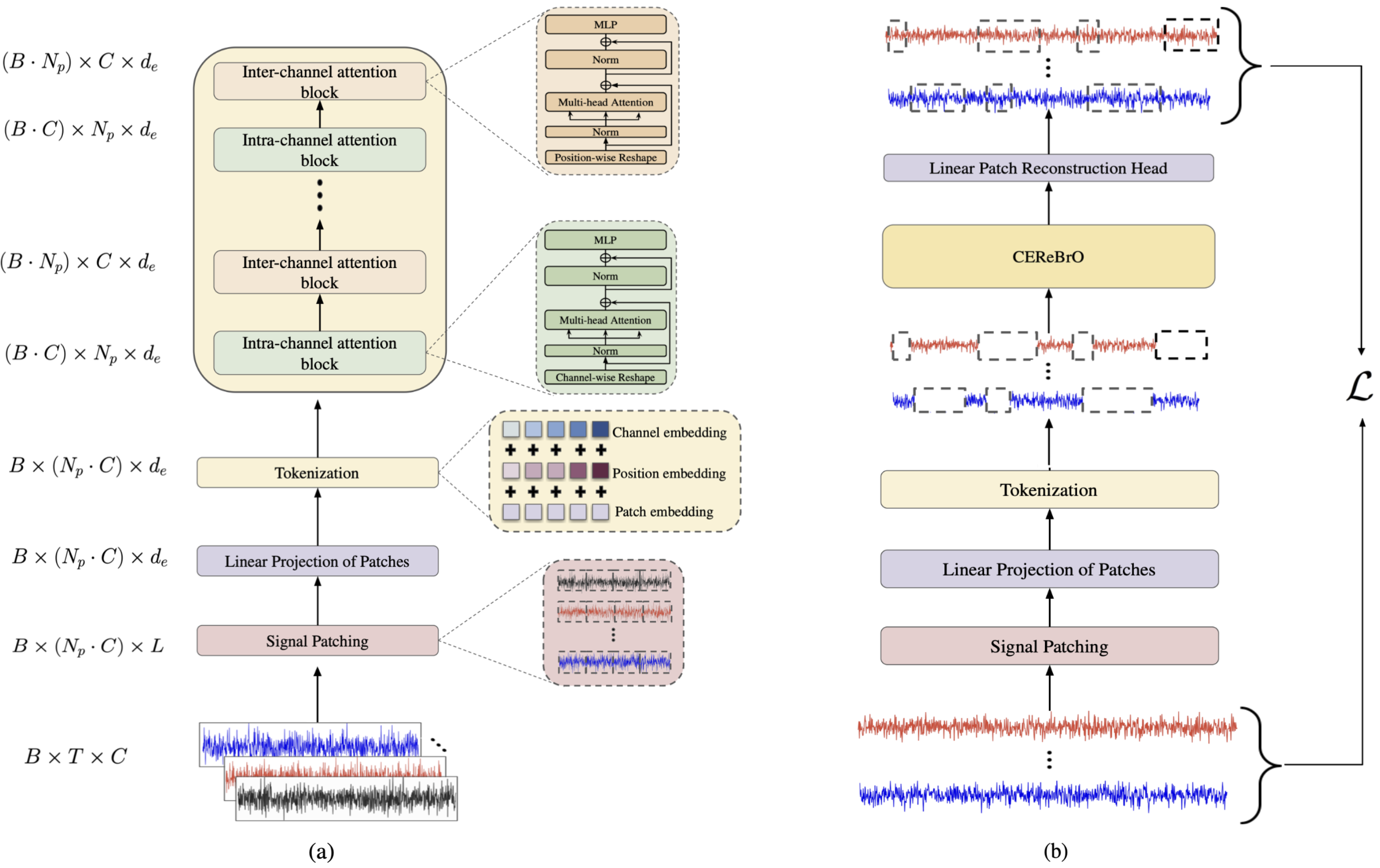
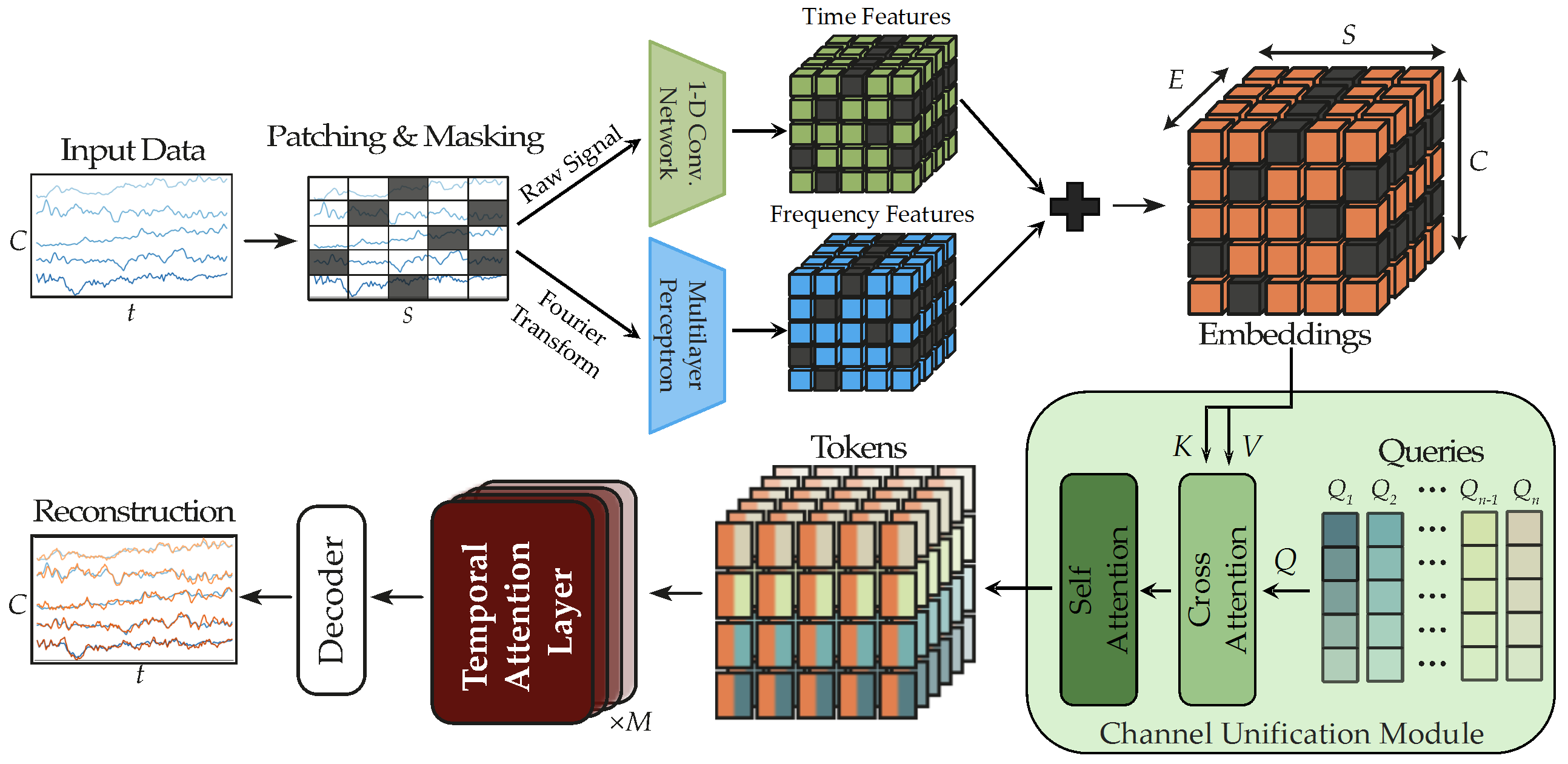
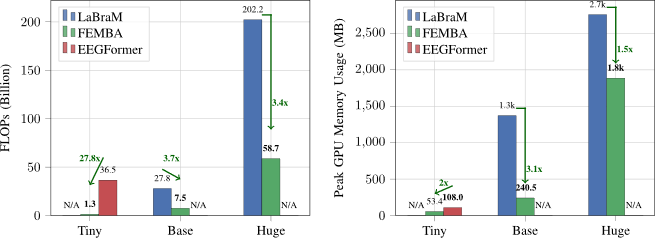
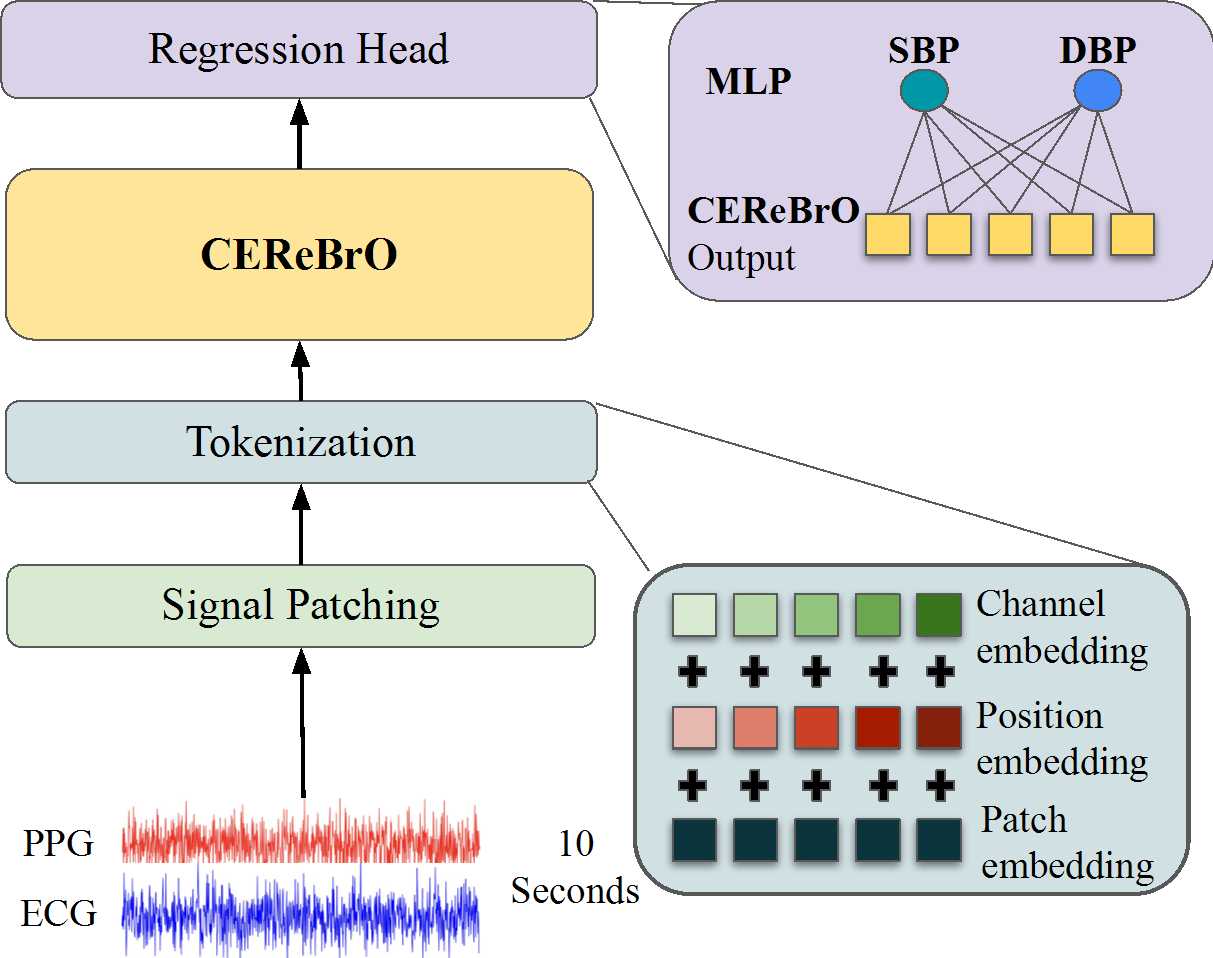
- Foundation model for biosignals: Biosignals capture physiological activities of human beings and find wide applications in healthcare, disease monitoring and detection, BCI, HCI, AR/VR, etc. These applications usually involves efficient on-device computation and accurate modelling capacity. This is an area that I’m interested in recently (PhysioWave, LUNA, WaveFormer, FEMBA, CEReBrO).
News
| Jan 20, 2026 | I’m awarded the prestigious Nanyang Assistant Professorship. I will be joining Nanyang Technological University soon. Stay tuned for upcoming opportunities for Research Assistant, Research Associate, and Research Fellow positions. |
|---|---|
| Sep 18, 2025 | Three papers on foundation models are accepted to NeurIPS 2025! One paper is on multimodal biosignal foundation model, one is on topology-agnostic EEG foundation model, and another one on segment anything in camouflaged videos with SAM2. Congrats Yanlong, Berkay, and Yuli. |
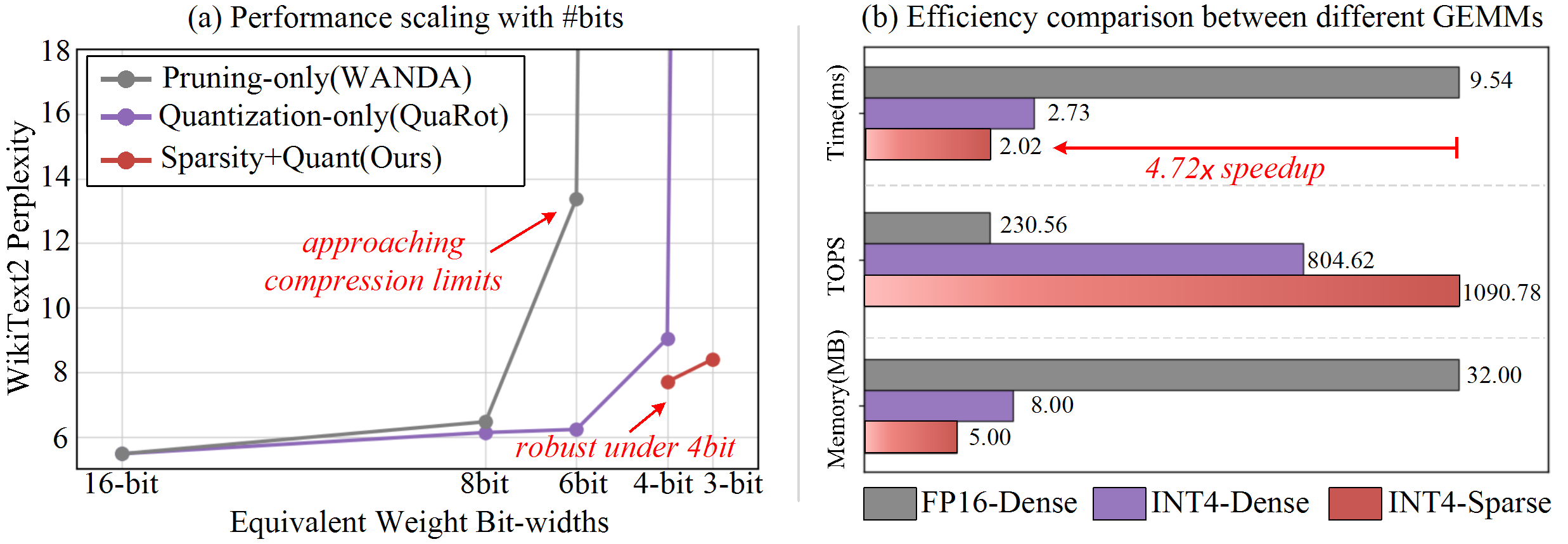
| Sep 14, 2025 | One work on joint quantization and sparsification is released on arxiv. In this work, we propose an error compensation method to reconcile the conflicting requirements of quantization and pruning. The proposed method delivers up to 4.72x speedup and 6.4x memory reduction compared to the FP16-dense baseline. |
| Aug 05, 2025 | One work Waveformer is accepted to NER 2025! In this paper, Wavelet transform is introduced to develop a transformer model for gesture recognition with EMG signals. |
| Aug 02, 2025 | One paper on AI/ML acceleration on edge device is accepted to CASES in conjunction with ESWEEK! |
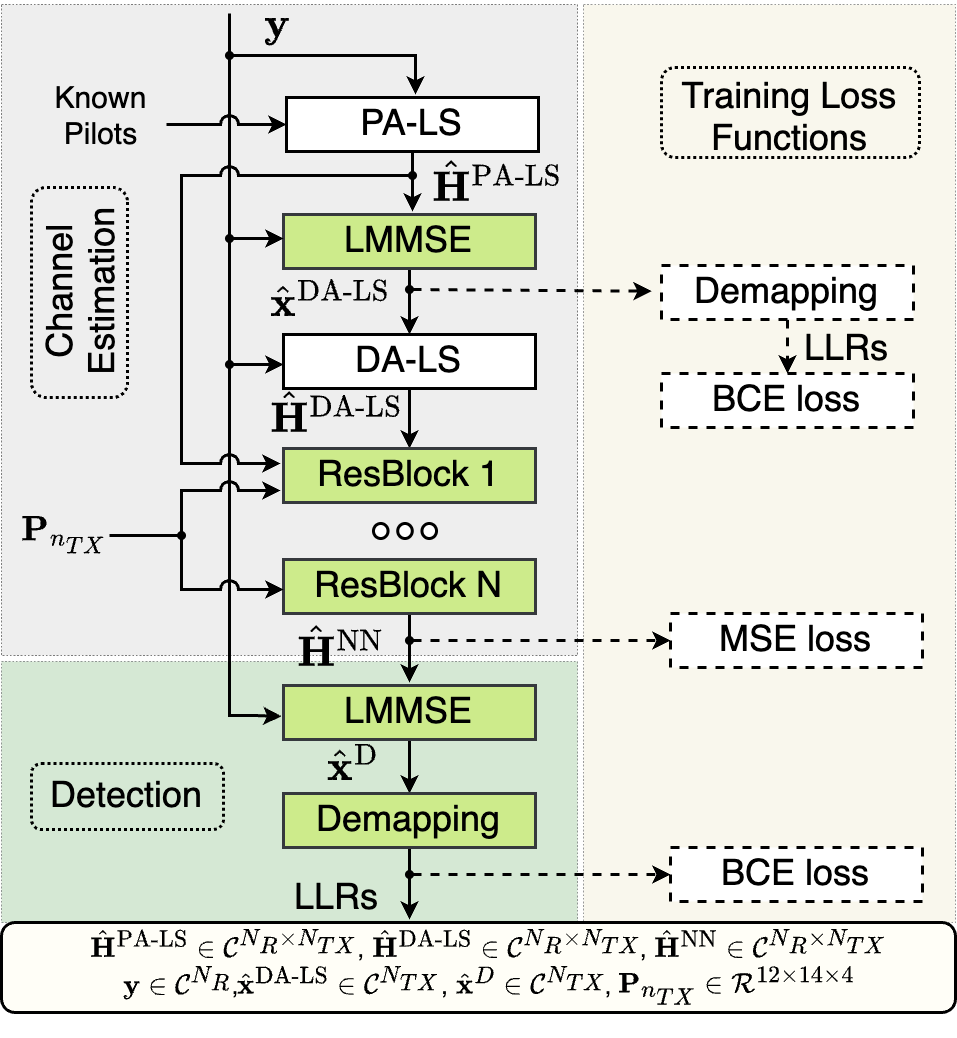
| Aug 01, 2025 | One paper is accepted to GLOBECOM 2025! The paper introduces a compute and memory efficient model for 5G receiver on the edge devices. |
| Jun 25, 2025 | One paper on the acceleration of visual autoregressive models is accepted to ICCV 2025! Check the paper here. |
| May 11, 2025 | One paper on dataflow and accelerator co-design is accepted to ISVLSI 2025! Check the paper here. |
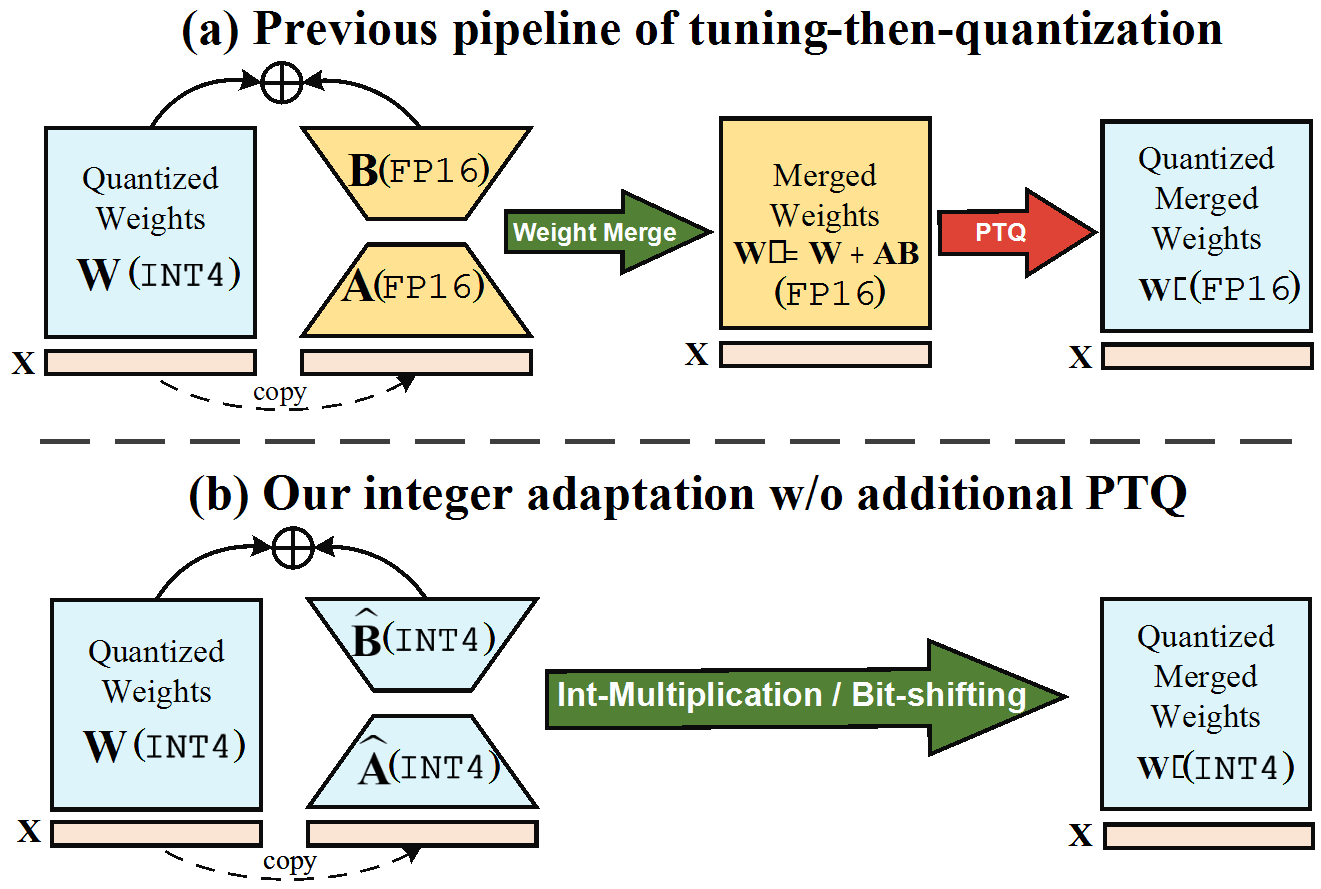
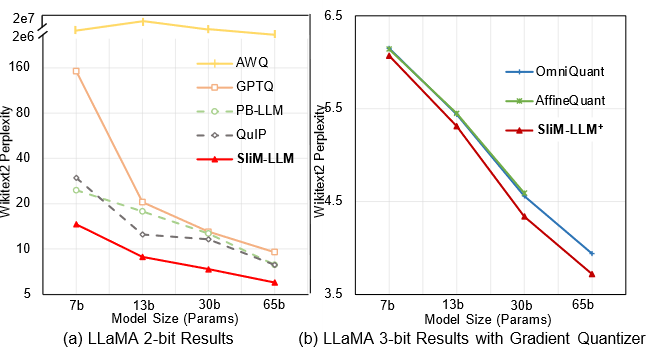
| May 01, 2025 | Two papers on model quantization are accepted to ICML 2025! IntLoRA proposes an integral low-rank adaption method for quantized diffusion models. After low-rank adaptation, all the weights are converted to integers. SliM-LLM proposes a mixed precision quantization method for LLMs. |
| Apr 29, 2025 | Two papers on biosignal foundation models are accepted to EMBC 2025! One paper introduces FEMBA, a state-space model for efficient and scalable EEG analysis. The other paper develops a model for blood pressure estimation with ECG and PPG signals. |
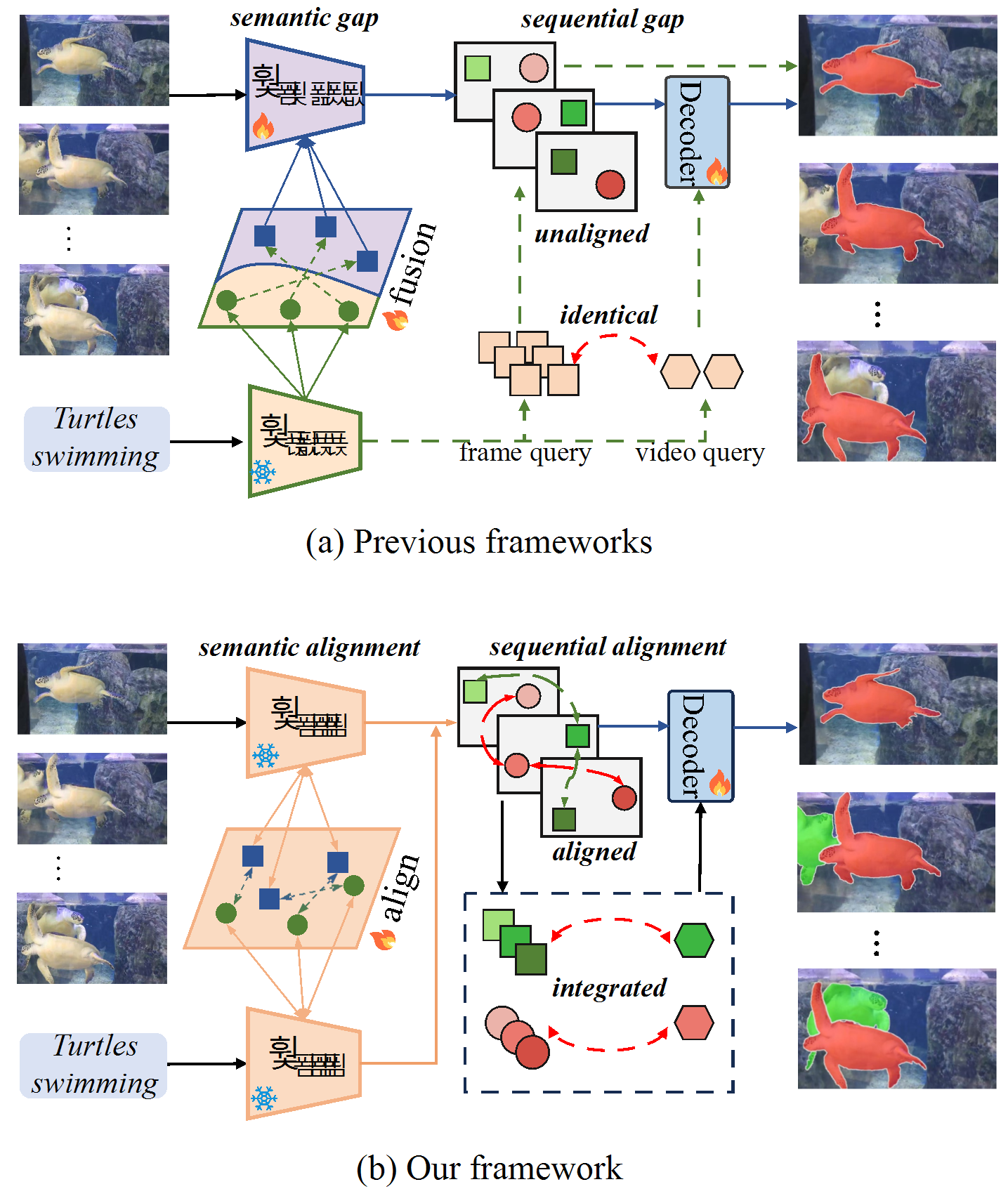
| Feb 26, 2025 | Three papers are accepted to CVPR 2025! One paper is on state space models, one is on foundation models for Markush structures, and another one on semantic and sequential alignment for vision-language models. |
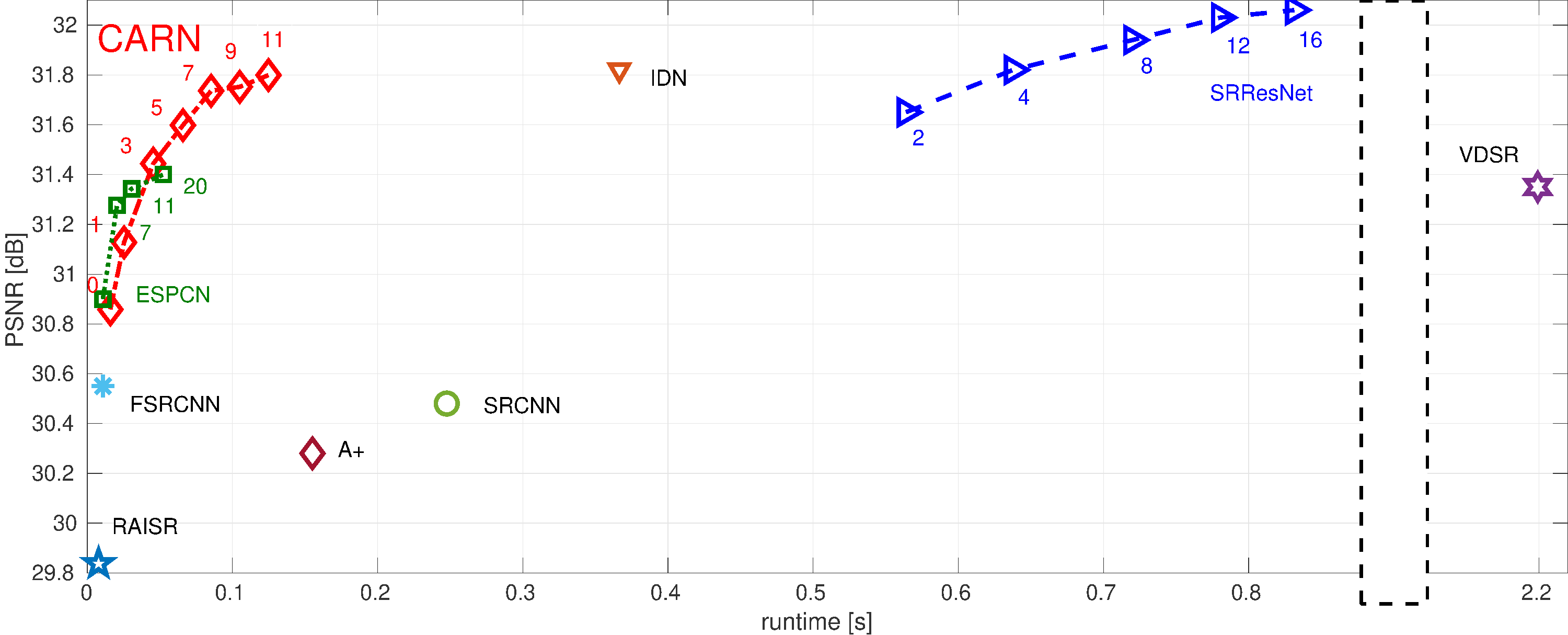
| Jan 18, 2025 | We are organizing the 10th NTIRE workshop and challenge on efficient image super-resolution and image denoising. |
| Sep 26, 2024 | One paper on Graph Attention in Transformers is accepted to NeurIPS 2024! Check the paper here. |
| Sep 25, 2024 | One paper on masked autoencoder for point clouds is accepted to ACCV 2024! Check the paper here. |
| Aug 30, 2024 | TinyTracker is accepted to IEEE Sensors. Check the paper here. |
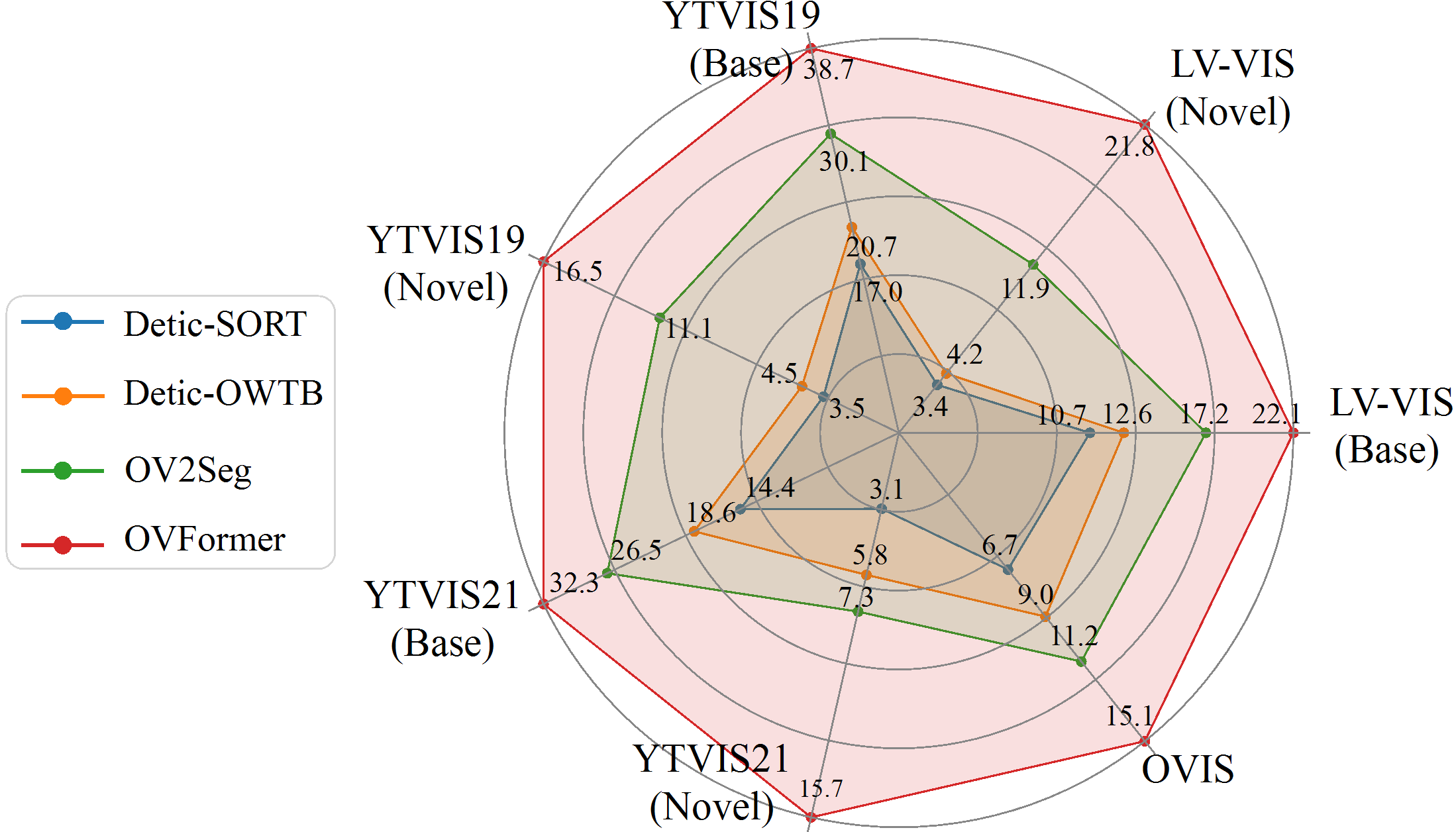
| Jul 01, 2024 | One paper on Open-Vocabulary Video Segmentation is accepted to ECCV 2024! Check the paper here. |
| Apr 30, 2024 | LSDIR dataset is accepted as a workshop paper at CVPR 2023. Check the paper here. |
| Mar 12, 2024 | One paper is accepted to ICME. Check the paper here. |
| Mar 01, 2024 | We open PhD positions on Secure Machine Learning on RISC-V Servers and Accelerators at ETH Zürich. More info here. |
| Feb 27, 2024 | VRT is accepted to IEEE TIP! Check the paper here. |
| Feb 27, 2024 | One paper is accepted to CVPR 2024! Check the paper here. |
| Jan 11, 2024 | We are organizing the 9th NTIRE Challenge on Efficient Super-Resolution. Check it here and here. |
| Dec 01, 2023 | I start as a Lecturer at ETH Zürich! |
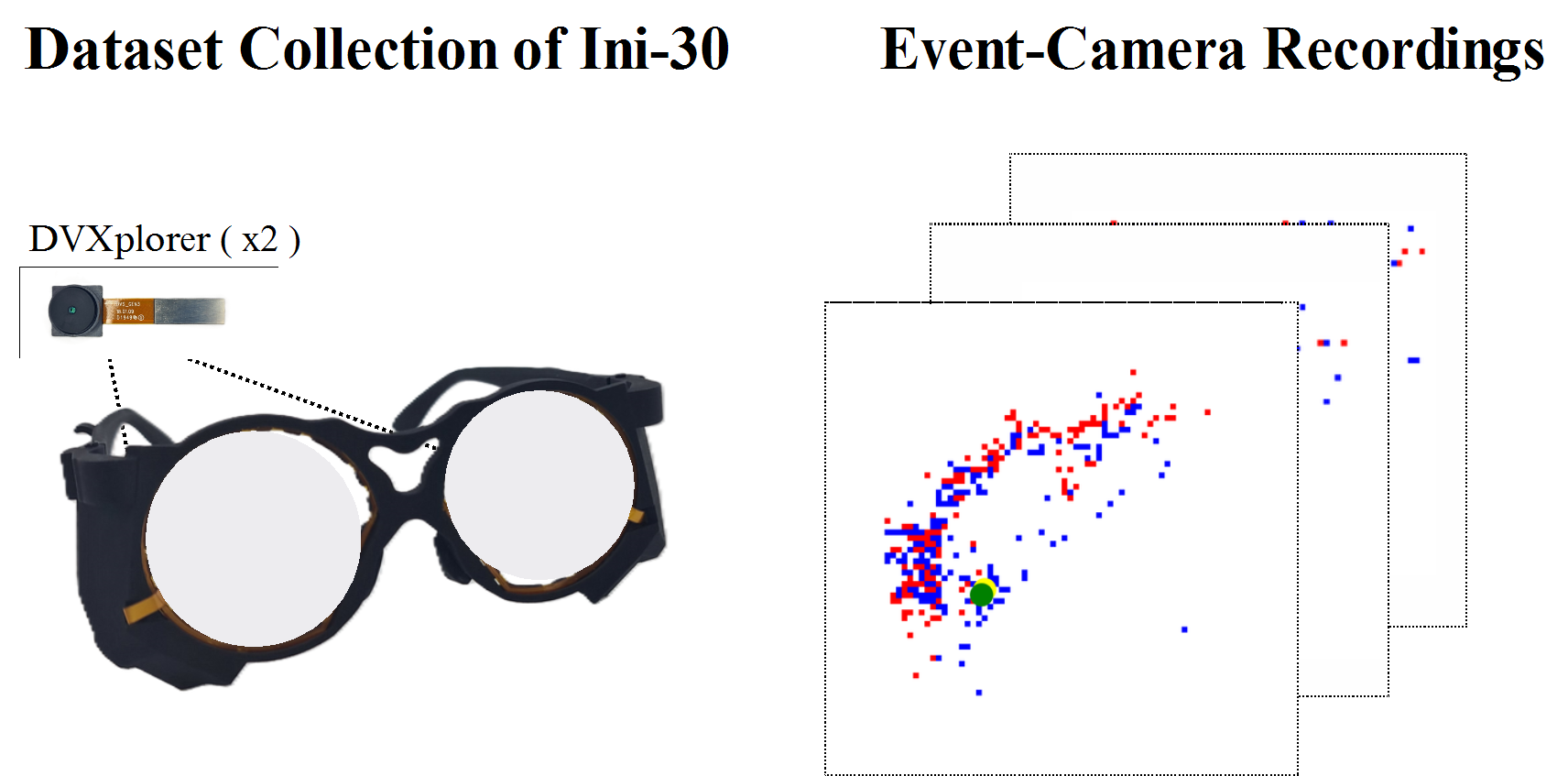
| Nov 04, 2023 | Our work on smart glasses is online. Check the paper here. |
| Sep 30, 2023 | One paper is accepted to Machine Intelligence Research. Check the paper here. |
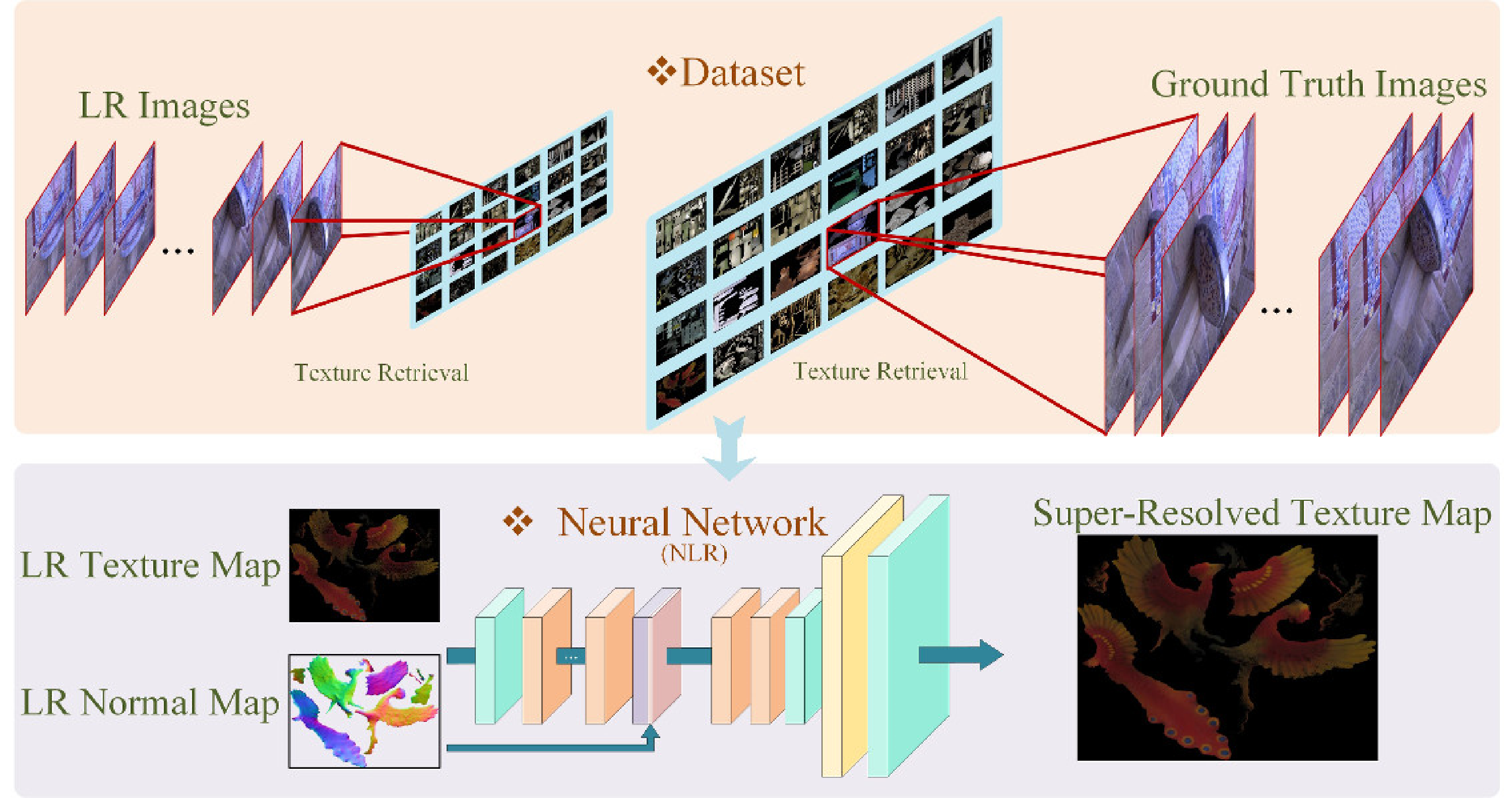
| Jul 03, 2023 | One paper on reference-based SR is accepted to ECCV 2022. |
| Apr 01, 2023 | I start as a Postdoc researcher at the Computer Vision Lab of ETH Zürich! |
| Feb 27, 2023 | Two papers are accepted to CVPR 2023! Check the papers here and here. GRL sets the new state-of-the-art for 7 image restoration tasks. Check GRL here. |
| Jan 01, 2023 | We are organizing the NTIRE 2023 Challenge on Efficient Super-Resolution, Image Denoising, and Image Super-Resolution (x4). More info here. |
| Mar 02, 2022 | Random pruning paper is accepted to CVPR 2022! Check the paper here. |
| Feb 16, 2022 | I defended my thesis! Check it here. |
| Jan 01, 2022 | We are organizing the NTIRE 2022 Challenge on Efficient Super-Resolution. More info here. |
| Jul 22, 2021 | Efficient GCN paper is accepted to ICCV 2021! Check the paper here. |
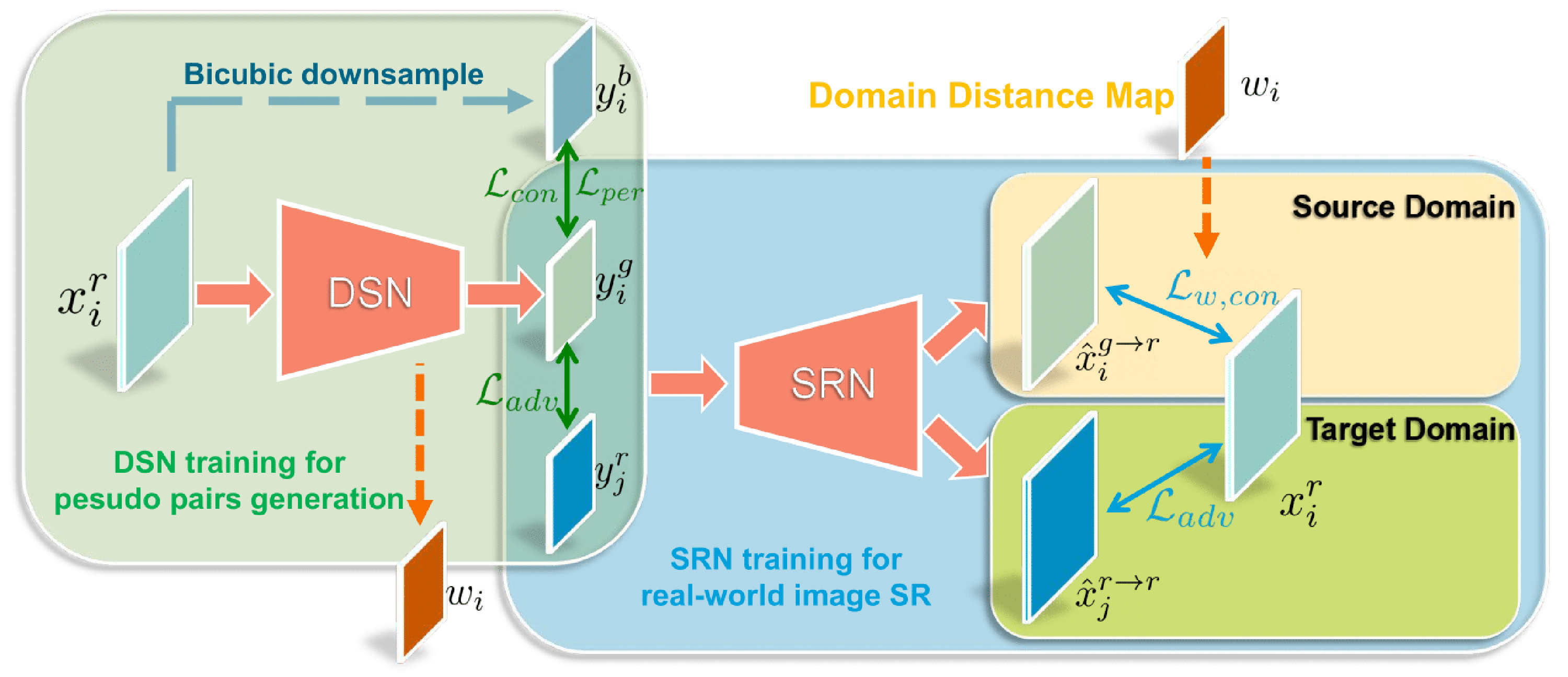
| Feb 28, 2021 | Three papers are accepted to CVPR 2021! Check the papers: The Heterogeneity Hypothesis, DASR, MOCDA. |
| Jul 03, 2020 | DHP paper is accepted to ECCV 2020! Check the paper here. |